* 본 포스팅은 나동빈 - 이코테 2021 강의 몰아보기 에서 학습한 내용을 포스팅합니다.
출처
■ 이진 탐색
● 순차 탐색 : 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 확인하는 방법
● 이진 탐색 : 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀나가며 데이터를 탐색하는 방법
- 이진 탐색은 시작점, 끝점, 중간점을 이용하여 탐색 범위를 설정
■ 이진 탐색 알고리즘 예시
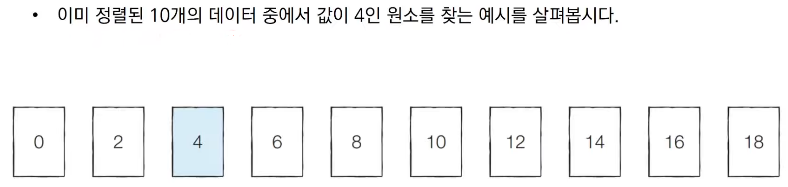
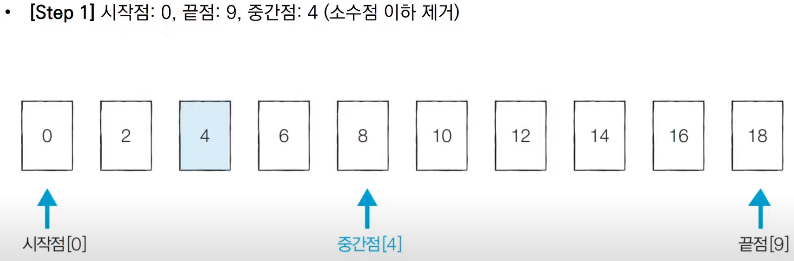
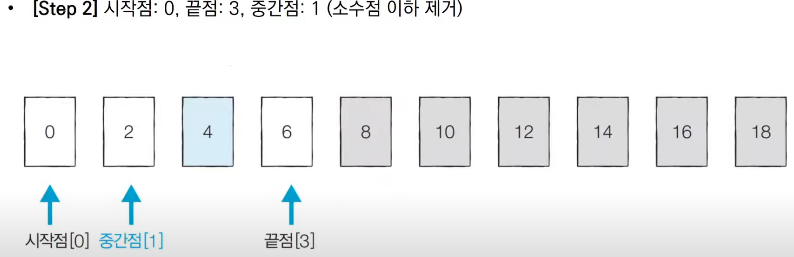
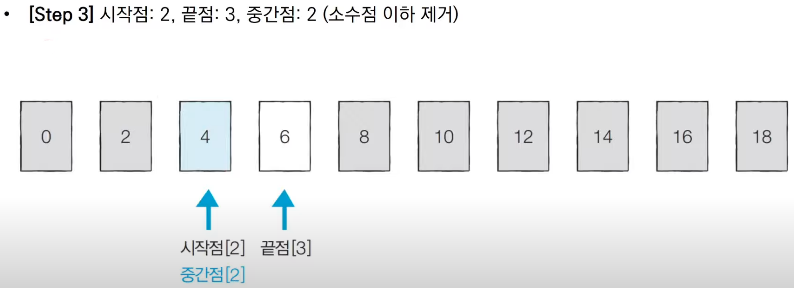
■ 이진 탐색의 시간 복잡도
● 단계마다 탐색 범위를 2로 나누는 것과 동일하므로 연산 횟수는 logN에 비례한다.
● 예를 들어 초기 데이터 개수가 32개일 때, 이상적으로 1단계를 거치면 16개 가량의 데이터만 남는다.
- 2단계를 거치면 8개 가량의 데이터만 남는다.
- 3단계를 거치면 4개 가량의 데이터만 남는다.
● 다시 말해 이진 탐색은 탐색 범위를 절반씩 줄이며, 시간 복잡도는 O(logN)을 보장한다.
■ 이진탐색 정렬 소스코드 : 재귀적 구현(Python)
# 이진 탐색 소스코드 구현 (재귀 함수)
def binary_search(array, target, start, end):
if start > end:
return None
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
return binary_search(array, target, start, mid - 1)
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
return binary_search(array, target, mid + 1, end)
# n(원소의 개수)과 target(찾고자 하는 값)을 입력 받기
n, target = list(map(int, input().split()))
# 전체 원소 입력 받기
array = list(map(int, input().split()))
# 이진 탐색 수행 결과 출력
result = binary_search(array, target, 0, n - 1)
if result == None:
print("원소가 존재하지 않습니다.")
else:
print(result + 1)
■ 이진탐색 정렬 소스코드 : 반복문 구현(Python)
# 이진 탐색 소스코드 구현 (반복문)
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
end = mid - 1
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
start = mid + 1
return None
# n(원소의 개수)과 target(찾고자 하는 값)을 입력 받기
n, target = list(map(int, input().split()))
# 전체 원소 입력 받기
array = list(map(int, input().split()))
# 이진 탐색 수행 결과 출력
result = binary_search(array, target, 0, n - 1)
if result == None:
print("원소가 존재하지 않습니다.")
else:
print(result + 1)
■ 파이썬 이진 탐색 라이브러리
● bisect_left(a, x):정렬된 순서를 유지하면서 비열 a에 x를 삽입할 가장 왼쪽 인덱스를 반환
● bisect_right(a, x):정렬된 순서를 유지하면서 배열 a에 x를 삽입할 가장 오른쪽 인덱스를 반환
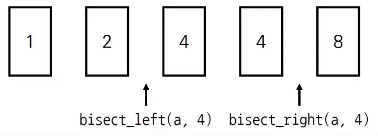
from bisect import bisect_left, bisect_right
a = [1, 2, 4, 4, 8]
x = 4
print(bisect_left(a, x)) # 2
print(bisect_right(a, x)) # 4
■ 값이 특정 범위에 속하는 데이터 개수 구하기
from bisect import bisect_left, bisect_right
# 값이 [left_value, right_value]인 데이터의 개수를 반환하고 함수
def count_by_range(a, left_value, right_value):
right_index = bisect_right(a, right_value)
left_index = bisect_left(a, left_value)
return right_index - left_index
# 배열 선언
a = [1, 2, 3, 3, 3, 3, 4, 4, 8, 9]
# 값이 4인 데이터 개수 출력
print(count_by_range(a, 4, 4)) # 2
# 값이 [-1, 3] 범위에 있는 데이터 개수 출력
print(count_by_range(a, -1, 3)) # 6▲ 오른쪽 인덱스와 왼쪽 인덱스를 빼면 해당 값의 범위에 포함되어 있는 데이터의 개수를 구할 수 있다.
4인 데이터의 개수를 구할려면 left와 right를 둘 다 4로 한다.
■ 파라메트릭 서치(Parametric Search)
● 파라메트릭 서치란 최적화 문제를 결정 문제('예' 혹은 '아니요')로 바꾸어 해결하는 기법
- 예시: 특정 조건을 만족하는 가장 알맞은 값을 빠르게 찾는 최적화 문제
● 일반적으로 코딩 테스트에서 파라메트릭 서치 문제는 이진 탐색을 이용하여 해결할 수 있다.
[문제] 떡볶이 떡 만들기
절단기에 높이(H)를 지정하면 줄지어진 떡을 한 번에 절단한다. 높이가 H보다 긴 떡은 H 위의 부분이 잘릴 것이고, 낮은 떡은 잘리지 않는다. 예를 들어 높이가 19, 14, 10, 17cm 인 떡이 나란히 있고 절단기 높이를 15cm로 지정하면 자른 뒤 떡의 높이는 15, 14, 10, 15cm가 될 것이다. 잘린 떡의 길이는 차례로 4, 0, 0, 2cm이다. 손님은 6cm 만큼의 길이를 가져간다.
손님이 왔을 때 요청한 총 길이가 M일 때 적어도 M 만큼의 떡을 얻기 위해 절단기에 설정할 수 있는 높이의 최댓값을 구하는 프로그램을 작성

■ 문제 해결 아이디어
● 적절한 높이를 찾을 때까지 이진 탐색을 수행하여 높이 H를 반복해서 조정
● '현재 이 높이로 자르면 조건을 만족할 수 있는가?'를 확인한 뒤 조건의 만족 여부에 따라서 탐색 범위를 좁혀서 해결
● 절단기의 높이는 0부터 10억까지의 정수 중 하나이다
- 이렇게 큰 탐색 범위를 보면 가장 먼저 이진 탐색을 떠올려야 한다.
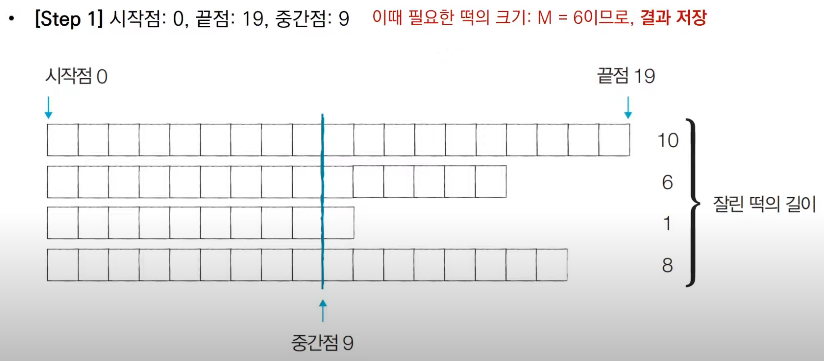
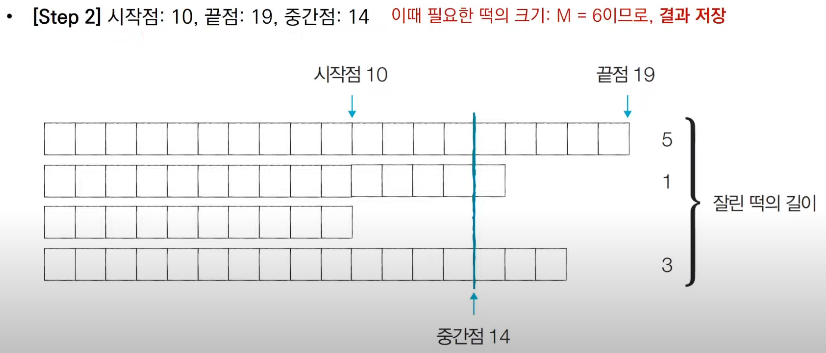


● 이러한 이진 탐색 과정을 반복하면 답을 도출할 수 있다.
● 중간점의 값은 시간이 지날수록 '최적화된 값'이기 때문에, 과정을 반복하면서 얻을 수 있는 떡의 길이 합이 필요한 떡의 길이보다 크거나 같을 때마다 중간점의 값을 기록하면 된다.
■ 답안 예시(Python)
# 떡의 개수(N)와 요청한 떡의 길이(M)을 입력
n, m = list(map(int, input().split(' ')))
# 각 떡의 개별 높이 정보를 입력
array = list(map(int, input().split()))
# 이진 탐색을 위한 시작점과 끝점 설정
start = 0
end = max(array)
# 이진 탐색 수행 (반복적)
result = 0
while(start <= end):
total = 0
mid = (start + end) // 2
for x in array:
# 잘랐을 때의 떡의 양 계산
if x > mid:
total += x - mid
# 떡의 양이 부족한 경우 더 많이 자르기(왼쪽 부분 탐색)
if total < m:
end = mid - 1
# 떡의 양이 충분한 경우 덜 자르기 (오른쪽 부분 탐색)
else:
result = mid # 최대한 덜 잘랐을 때가 정답이므로, 여기서 result에 기록
start = mid + 1
# 정답 출력
print(result)
[문제] 정렬된 배열에서 특정 수의 개수 구하기
● N개의 원소를 포함하고 있는 수열이 오름차순으로 정렬되어 있다. 이때 이 수열에서 x가 등장하는 횟수를 계산해라.
예를 들어 수열 {1, 1, 2, 2, 2, 2, 3}이 있을 때 x = 2라면, 현재 수열에서 값이 2인 원소가 4개이므로 4를 출력한다.
● 단, 이 문제는 시간 복잡도 O(logN)으로 알고리즘을 설계하지 않으면 시간초과 판정을 받는다.

■ 문제 해결 아이디어
● 시간 복잡도 O(logN)으로 동작하는 알고리즘을 요구한다.
- 일반적인 선형 탐색(Linear Search)으로 시간 초과 판정을 받는다.
- 하지만 데이터가 정렬되어 있기 때문에 이진 탐색을 수행
● 특정 값이 등장하는 첫 번째 위치와 마지막 위치를 찾아 위치 차이를 계산해야 문제를 해결할 수 있음.
■ 답안 예시(Python)
from bisect import bisect_left, bisect_right
# 값이 [left_value, right_value]인 데이터의 개수를 반환하는 함수
def count_by_range(array, left_value, right_value):
right_index = bisect_right(array, right_value)
left_index = bisect_left(array, left_value)
return right_index - left_index
n, x = map(int, input().split()) # 데이터의 개수 N, 찾고자 하는 값 x 입력받기
array = list(map(int, input().split())) # 전체 데이터 입력받기
# 값이 [x, x] 범위에 있는 데이터의 개수 계산
count = count_by_range(array, x, x)
# 값이 x인 원소가 존재하지 않는다면
if count == 0:
print(-1)
# 값이 x인 원소가 존재한다면
else:
print(count)
'알고리즘' 카테고리의 다른 글
| [알고리즘] 다이나믹 프로그래밍 (2) (0) | 2023.02.16 |
|---|---|
| [알고리즘] 다이나믹 프로그래밍 (1) (0) | 2023.02.15 |
| [알고리즘] 정렬 (2) (0) | 2023.02.11 |
| [알고리즘] 정렬 (1) (0) | 2023.02.11 |
| [알고리즘] DFS & BFS (2) (0) | 2023.02.08 |




댓글